看了两周多的spark,也是时候把自己看的杂七杂八的内容输出一下了。
MapReduce和Hadoop几乎已经成为分布式计算的代名词,并且在大规模数据的处理中起着重要的作用。
但是MapReduce框架却存在着一些问题,使得它在某些问题上,表现较差,主要的原因它缺乏对内存更好的利用,向上提供关于内存的抽象,而且在数据运算过程中出现的中间结果,也都保存在硬盘上,对于某些类型的计算而言,比如对一个大规模的数据集进行一次count,这样是没有问题的。因为计算的流向只需要从每个结点流向最后的结果结点。而且这个流向只进行一次。
但是对于某些类型的计算,这个问题却很严重。
最主要的有机器学习和交互数据挖掘,在机器学习中,大量的学习问题最后被归为一个参数优化问题,这个参数优化问题需要不断地迭代运算。而每次运算的中间结果都作为下一次运算的输入再次进行。如果使用MapReduce来处理这样的问题,MapReduce只能将中间的运算结果写入分布式文件系统如Hadoop中的HDFS,进行使用,在这个过程中,花费在磁盘IO,数据复制以及序列化上的操作大大拖慢了系统了速度。这些操作都是十分耗时的。
另一个问题是交互式数据挖掘,在这种计算中,用户可能对数据集中的某一个子集进行多次的特定查询。对于MapReduce而言,这种数据的重用仍然只能通过写入外部分布式存储来进行。
spark正是设计来解决这样的问题的。
|
|
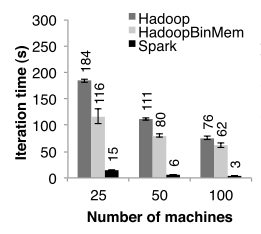
spark的设计者Matei Zaharia等人在亚马逊云计算平台EC2上做了实验,在4核心15G内存、使用HDFS分布式文件系统的运行环境中,Zaharia运行了逻辑回归这样的迭代任务,spark的表现比Hadoop要快25倍左右。而根据作者说在生产环境中,spark更是要快上40倍。 |
spark最主要的设计就是对内存的抽象,其核心概念是所谓的可伸缩分布式数据集(RDD)。下面就来介绍这个RDD。
我的理解,RDD就是spark的计算单元,spark对一个一个可迭代,或者可分解的任何的任何,分解成多个RDD,每个RDD包含数据和指定的操作,然后这个RDD被分配给不同的结点,进行计算,计算的结果再汇总到主结点进行结合。并返回计算结果。
举例来说,对一个3GB的文件,进行计算,算其到底包含了”十三很帅”的总行数,那么在这种情况下,spark应该是读取这个文件,然后将截成一个个的文件块(如果本来就是分布式存储,那么可以更方便,根本就不需要截了),将count操作和这个文件块作为一个RDD,发送到某个计算结点,由这个计算结点对RDD进行操作。最后再返回计算结果,并进行合并汇总。
再来看一个定义:
RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。
RDD有三个主要的特点,它具有较高的容错性,是对内存进行的抽象,同时支持集群计算。
从静态表示上来说,RDD一般由五个部分的通用接口来表示。
我们以spark的某个python示例为例。
tc = sc.textFile(“十三好帅.txt’)
# 读取文件
wordRDD = tc.flatMap(lambda x: jieba.cut(x))
# 对文件中的每行进行分词,从一个lineRDD,转换到一个wordRDD
wordFreRDD = wordRDD.map(lambda x: (x, 1))
# 又是一次RDD的转换,将每个word,转换成(word, count)的形式
counts = wordFreRDD.reduceByKey(add)
# 使用加法操作,将这个频次计数对,进行汇总合并。
一、数据分区,一个RDD中的数据可以分成多个数据分区,数据分区是RDD的最小计算单位。
二、依赖关系,指一个RDD是通过哪些父RDD生成的。比如wordRDD就是wordFreRDD的父RDD,但是注意一点,父RDD是指某一个RDD,代码中的wordRDD和wordFreRDD都是一类。
三、计算RDD的函数。例如上例中,使用lambda定义的算子,都属于此列。
四、每个数据分片的预定义地址列表(如HDFS上的数据块的地址)【可选】
五、对于hash/range型的RDD的元数据。
下一章,我们来讨论RDD的独特设计,以及与之前的分布式系统的不同之处,并仔细了解下它是如何实现快速容错的能力的。