最近参加完mla2014,深感自己基础还是甚不牢靠,之前断断续续的学习,没有一部内化的大部头做根基,一切都是无根之萍。
好在最近自己的生活节奏和状态都已经调节到看prml丝毫不觉得违和的地步,而且不再焦急地想把它看完,这样的学习状态应该是最好的。于是,进军PRML。
首先是训练集与测试集的概念,泛化,输入空间与输出空间,特征空间,特征提取,监督学习,非监督学习,分类与回归任务,这些都没有什么太多可说的。
此书中提到非监督学习的三个主要任务,聚类,density estimation,可视化,关于density estimation这个任务,之前没有怎么接触过,
以前和人讨论时,曾经被人问强化学习和监督学习的区别到底在什么地方,当时初一听感觉很清晰,仔细一想却又迷惑了,毕竟强化学习要给出一个反馈函数,而监督学习要给出一个损失函数,好像这两个大同小异的样子,仔细一想却是相当的不同,监督学习给出的是一个标准答案,而强化学习则是对agent某个动作的评价。
再有,监督学习的学习任务基本上可以算做是静态的,在这个训练集上训练完毕这个模型就完了。而强化学习,则需要执行同样的任务多次,其中会涉及到时间步的概念。
这样讲了半天,好像还是抓往监督学习和强化学习最本质的区别?
之前曾经做过写过强化学习的程序,过了快一年了,只记得当前的任务主要是学习反馈函数的具体参数,同时需要使用贝尔曼不等式来进行奖励最大化。
再使用一定的比例来控制exploration和exploitation,这个思想就非常的接地气,我们经常要在探索新的世界和利用已有世界的最好选择之间进行取舍,你遇到一个妹纸,感觉丫很合适,就这样从了么?这是利用已有世界的最优选择,还是再等等,看看有没有新的妹纸出现,这是探索新的世界。在这两种选择之间,分别使用什么样的概率值比较好,是在百分之八十的可能性下取当前最优呢,还是百分之八十的可能性下探索未知呢。百分之八十呢,还是五五对半分,一个agent的做法和一个人的做法一样,对于儿童,而言,会分配更多的可能性探索未知世界,对于老人而言,会分配更多的可能性利用已有最优。
这都是后话,到强化学习的时候再细说。
接着提到的一点说,关于机器学习中噪声的来源,在一些情况下,这种噪声是由于我们测量的问题,但更有可能是存在着某些未被观测到的信号源或者变量,由这个信号源导致的噪声。
之后,在谈在大众皆知的过拟合,模型选择等等问题之后,prml终于出现了书中的第一次的干货。
我们知道,一个函数可以通过其泰勒展开变化成多项式的形式,对于一个机器学习问题,如果使用多项式形式来做为hyposis,那么通过最小均方差,可以得到一个最优的参数w*
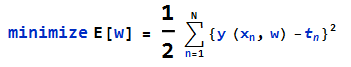
假设我们现在需要进行模型选择,也就是说,在多项式模型的模型空间中,选择一个M阶多项式作为我们最后的模型,那么
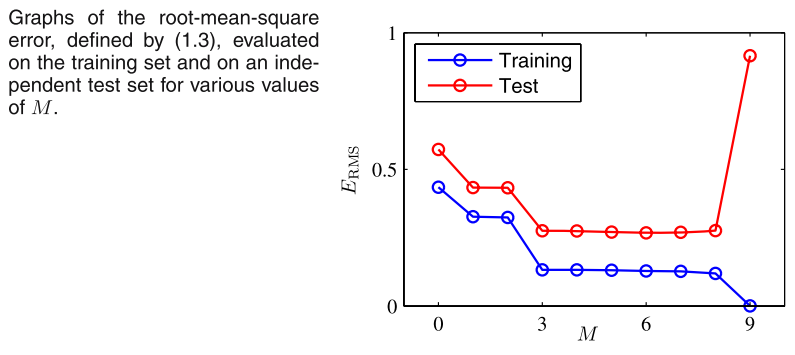
对于M=m来说,存在一个w(m)*,这是一个m+1维的向量(考虑w0),那么对于这个训练出来的最优参数w(m)*来说,在模型m下,最优的损失函数为E(w)*,基于此,我们可以定义模型m的一个度量root mean square
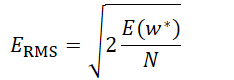
由于之前使用的损失函数,只是取了最小均方,因此RMS中首先除以N,对损失函数进行scale,这样对于如果不同的模型使用的训练集大小不同,就可以放在一起进行比较,其次再进行开方,开方之后,损失函数的量级就被还原到和目标向量同样的数据级上(因为之前计算损失函数进行了平方操作。)
在进行了这样的处理之后,就可以对于不同m进行比较了。
比较的结果如下: